


Redis
概述
Redis是一个开源、使用C语音编写、支持网络交互、内存中的key-value数据结构存储系统。它可以作为数据库、缓存和消息中间件。
它支持多种类型的数据结构,如字符串(String)、散列(hashes)、列表(list)、集合(set)、有序集合(sorted set)与范围查询,bitmaps,hyperloglogs和地理空间(geospatial)索引半径查询。
关系型数据库和非关系型数据库
关系型数据库
采用关系模型来组织数据的数据库,关系模型就是二维表格模型。一张二维表的表名就是关系,二维表中的第一行就是一条记录,二维表中的一列就是一个字段。
优点:
容易理解
使用方便,通用的sql语言
易于维护,丰富的完整性(实体完整性、参照完整性和用户定义的完整性),大大降低了数据冗余和数据不一致的概率缺点
缺点:
磁盘I/O是并发的瓶颈
海量数据查询效率低
横向扩展困难,无法简单的通过添加硬件和服务节点来扩展性能和负载能力
当需要对数据库进行升级和扩展时,需要停机维护和数据迁移
多表的关联查询以及复杂的数据分析的复杂sql查询,性能欠佳。因为要保证ACID。
非关系型数据库
非关系型,分布式,一般不保证遵循ACID原则的数据存储系统。键值对存储,结构不稳定。
优点:
根据需要添加字段,不需要多表联查。仅需要id取出对应的value
严格上讲不是一种数据库,而是一种数据结构化存储方法的集合
缺点:
只适合存储一些较为简单的数据
不适合复杂查询的数据
不适合持久存储海量数据
Linux远程连接命令
redis-cli -h HOST -p PORT -a PASSWDHOST(ip 例:127.0.0.1)
PORT (端口号)
PASSWD (redis密码)
Redis数据类型
Redis支持的5种数据类型:
string(字符串)
hash(哈希)
list(列表)
set(集合)
zset(sorted set:有序集合)
String(字符串)
string是redis最基本的类型,一个key对应一个value。
string类型是二进制安全的。意思是Redis的string可以包含任何数据。比如jpg图片或序列化的对象。
string类型的值最大能存储512MB。
实例:
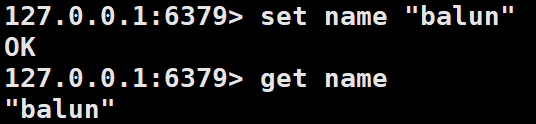
在以上实例中使用了Redis的SET和GET命令。键为name,对应的值是balun。
Hash(哈希)
redis hash是一个键值(key=>value)对集合。
redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
存的是字符串和字符串之间的映射,如L一个用户要存储全名、姓氏、年龄等等。
实例:
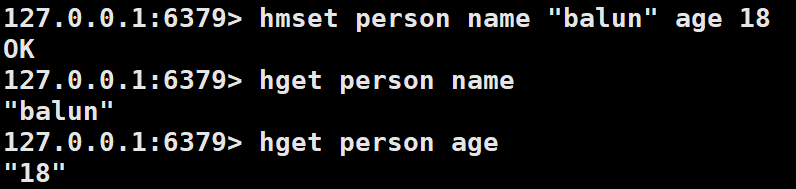
HMSET设置了两个filed=>value对,HGET获取对应field对应的value。
每个hash可以存储231-1 键值对(40多亿)。
常用指令:
HLEN keyName (查看指定Hash表的键值对数量)
HKEYS keyName (查看指定Hash表中的所有键)
HVALS keyName (查看指定Hash表中的所有值)
HGET keyName field (查看Hash表中指定键对应的值)
List(列表)
Redis列表是最简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列的头部或者尾部。

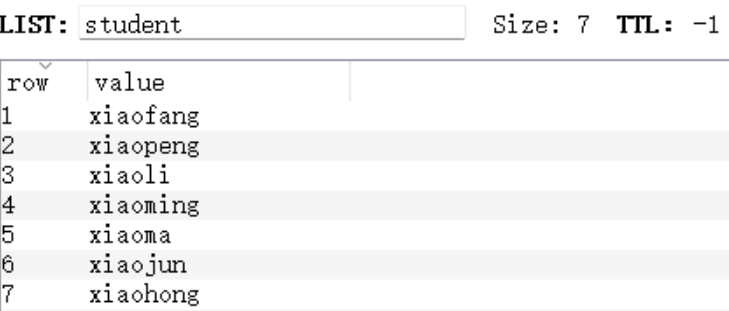
Set(集合)
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加、删除、查找的复杂度都是O(1)。
sadd命令
添加一个string元素到key对应的set集合中,成功返回1,如果元素已经在集合中,则返回0.
sadd key member实例:
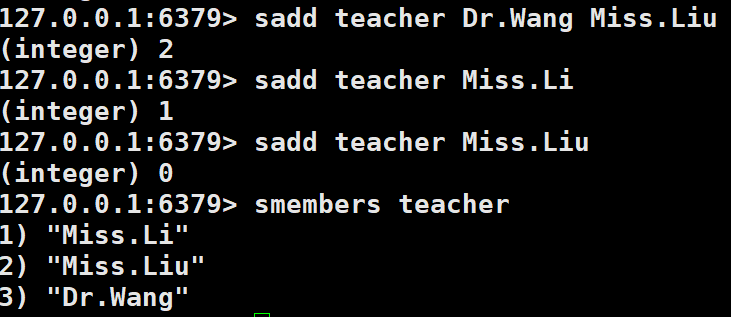
以上实例中,Miss.Liu添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。最大成员数为232 -1(约40多亿个)。
zset(sorted set:有序集合)
Redis zset和set一样也是string类型元素的集合,且不允许重复元素。
不同的是每个元素都会关联一个double类型的分数。Redis正是通过分数来为集合中的元素进行从小到大排序。
zset中的元素是唯一的,但分数可以重复。
zadd命令
添加元素到集合,元素在集合中存在则更新对应的分数(score)
zadd key score member实例:
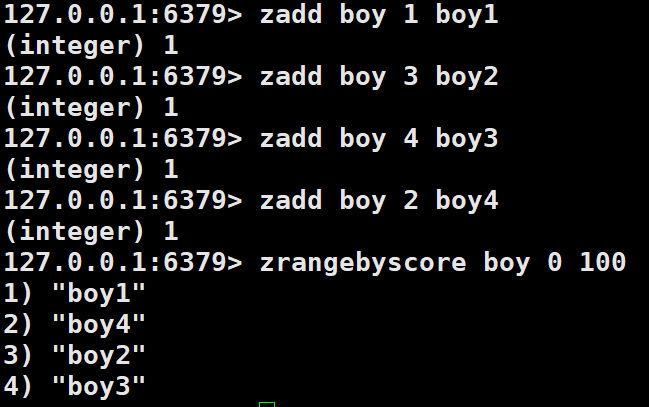
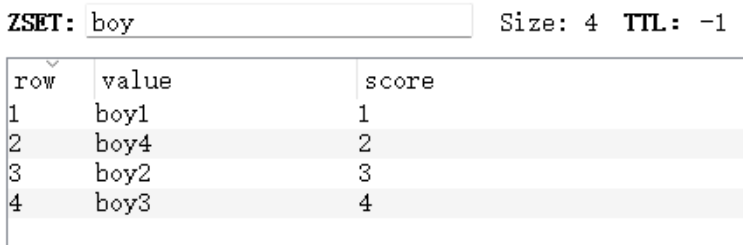
设置失效时间
有时候我们并不希望redis的key一直存在。例如缓存、验证码等数据,我们希望它们在一定时间后自动销毁。redis提供了一些命令,能够对key设置过期时间,让key过期之后自动删除。
设置值时直接设置有效时间
EX表示以秒为单位
PX表示以毫秒为单位 EX和PX不区分大小写
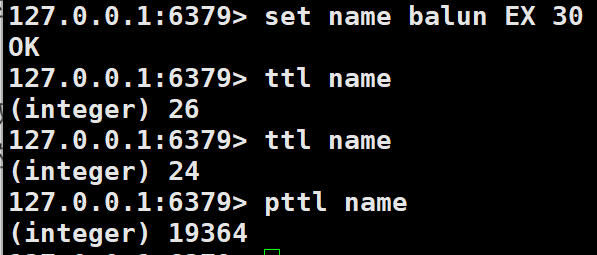
set name balun EX 30 设置失效时间为30秒
ttl 查看剩余时间(秒)
pttl 查看剩余时间(毫秒)设置值后设置有效时间
expire (秒)
pexpire (秒)过期key删除策略
1.定时删除
在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key过期时对key进行删除。
优点:
定时删除策略对内存是友好的,使用定时器可以保证过期键会尽快被删除,释放占用内存。
缺点:
对CPU不友好,在过期键比较多的情况下,删除过期键可能会占用一部分CPU时间,在内存不紧张但是CPU紧张的情况下,将CPU时间用在删除和当天任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。
创建一个定时器需要用到Redis服务器中的时间事件,而当前时间事件的实现方式——无序链表,查找一个事件的时间复杂度为O(N),并不能高效处理大量时间事件。
2.惰性删除
每次从数据库获取key的时候去检查是否过期,如果过期,就删除该键,否则就返回该键。
优点:
惰性删除策略对CPU是有好的,程序会在获取键时才对键进行过期检查,并且删除的目标仅限于当前处理的键,这个策略不会再删除其他无关的过期键上花费CPU时间。
缺点:
对内存不友好,如果一个键以及过期,只要这个键不被删除,它所占用的内存就不会被释放。如果数据库有很多过期键,而这些过期键又没有被访问到的话,那么他们永远不会被删除,除非手动执行flushdb。
3.定期删除
每隔一段时间,程序就对数据库进行检查,删除里面的过期键。
优点:
定期删除策略是前两种策略的一种整合和折中:
定期删除策略每隔一段时间执行一次删除过期键的操作,并通过限制删除操作执行的时长和频率来减少操作对CPU时间的影响。
定期删除策略有效的减少了因为过期键而带来的内存浪费。
缺点:
如果删除操作执行的太频繁,或执行时间太长,定期删除策略就退化为定时删除策略,以至于CPU时间过多的消耗在删除过期键上。
如果删除操作执行的太少,或者执行的时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况。
Redis采用的过期键删除策略
Redis服务器使用的是惰性删除和定期删除两种策略,通过配合使用这两种删除策略,服务器可以很好的合理利用CPU时间和避免浪费内存空间之间取得平衡。
主从复制
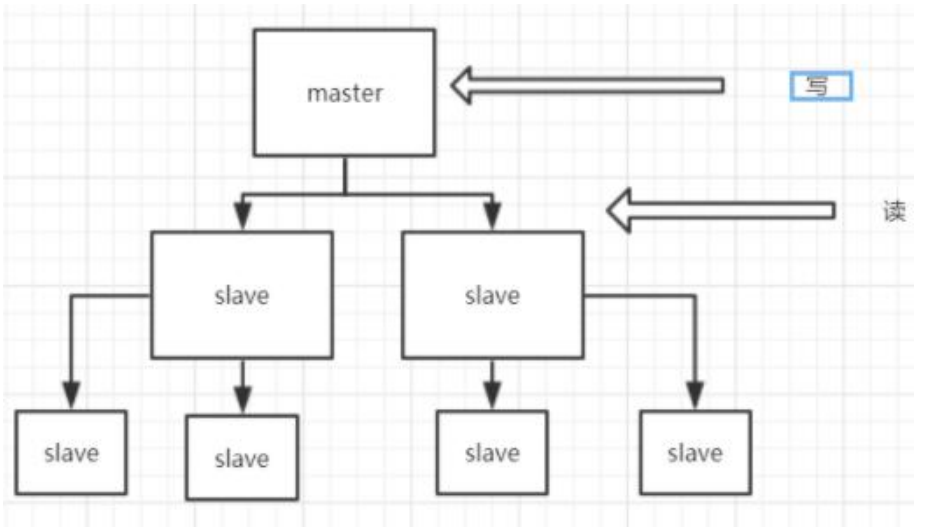
主从复制,是指将一台Redis服务器的数据,复制到其他Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
使用一个Redis实例作为主机,其余的作为备份机。主机和备份机的数据完全一致,主机支持数据的写入和读取各项操作,而从机则只支持与主机数据的同步和读取。也就是说客户端可以将数据写入主机中,由主机自动将数据的写入操作同步到从机。主从模式很好的解决了数据备份的问题,并且由于主从服务数据几乎是一致的,因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
主从复制的作用主要包括:
数据冗余:主从复制实现了数据的热备份,使持久化之外的一种数据冗余方式。
故障恢复:当主节点出现问题时,可以有从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
负载均衡:在主从机的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
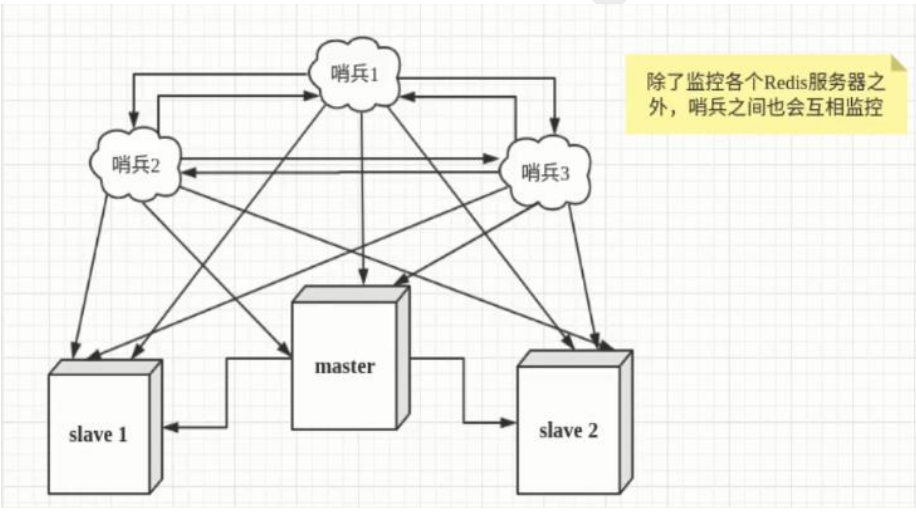
哨兵机制
概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
单哨兵
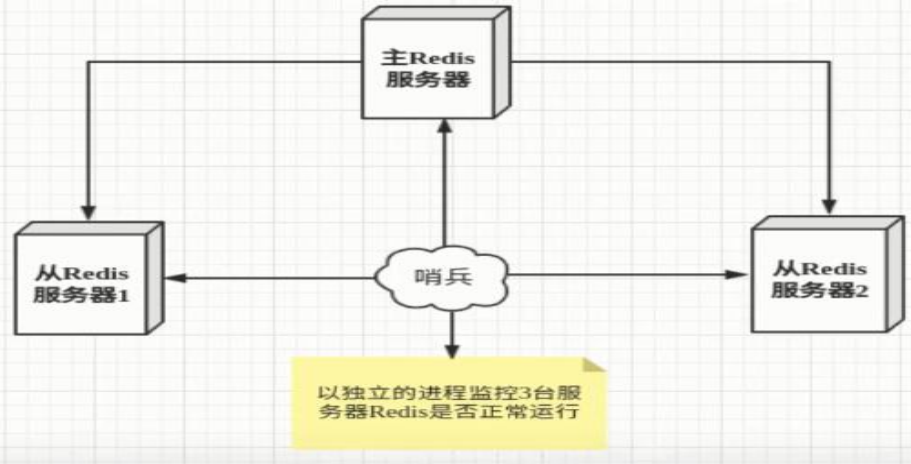
哨兵集群
缓存穿透、缓存击穿、缓存雪崩
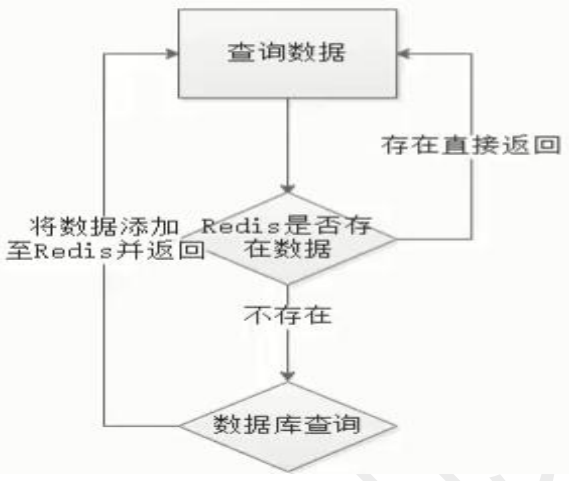
缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那返回空结果。
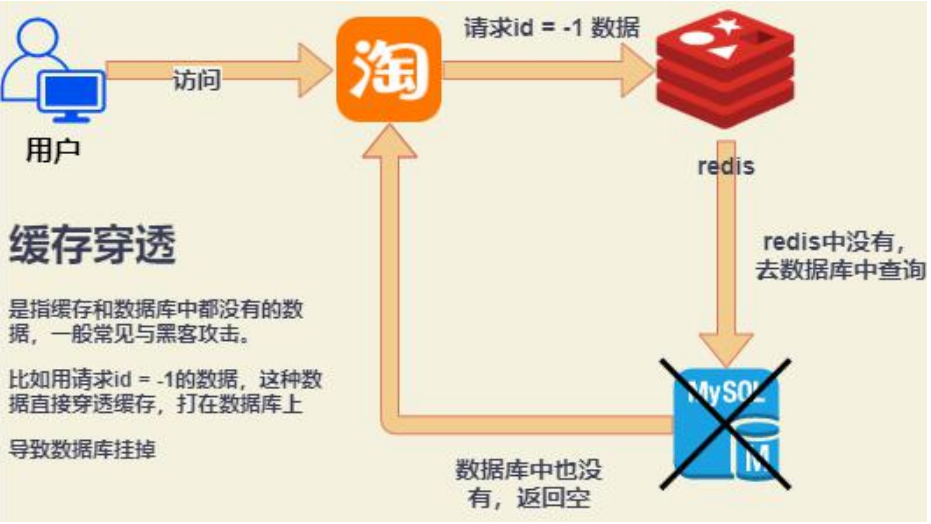
缓存穿透
key对应的数据在数据库中并不存在,每次针对此key的请求从缓存中获取不到,请求都会到数据库,从而可能压垮数据库。比如:用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击,可能压垮数据库。(数据库没有,缓存没有)
解决办法:
使用布隆过滤器(BloomFilter)或压缩filter提前拦截。
将这个空对象设置到缓存中取。下次在请求的时候直接从缓存中获取。(这种情况我们一般会将空对象设置一个较短的过期时间)。
拉黑该IP地址。
对参数进行校验,不合法参数进行拦截。
缓存击穿
某个key对应的数据库中存在,但是在redis中的某个时间节点过期了,此时若有大量并发请求过来,这些请求发现缓存过期,都会从后端DB加载数据并回设到缓存,这时大量并发请求可能会瞬间把后端DB压垮。(热点key突然过期)
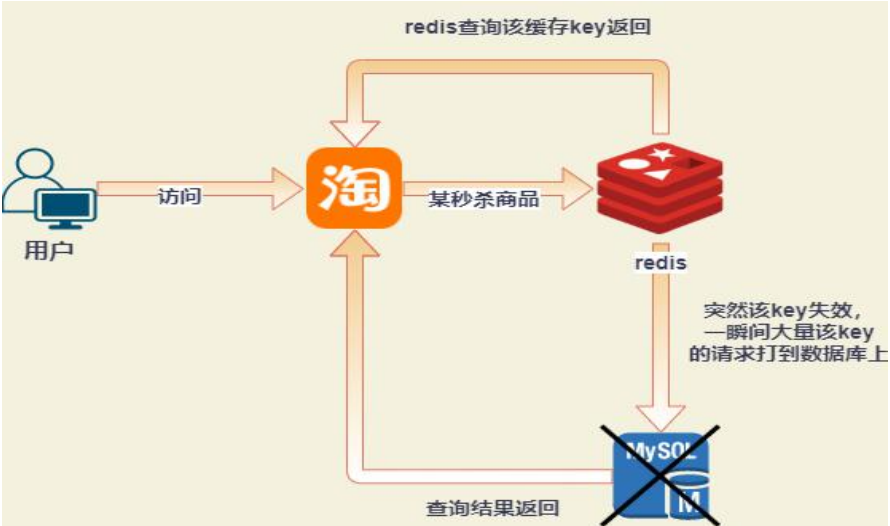
解决办法:
热点数据设置永不过期。
加上互斥锁:上面的现象是多个线程同时取查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个互斥锁来锁住它。其它的线程走到这一步拿不到锁就等待,等第一个线程查询到了数据,然后将数据放到Redis缓存起来,后面的线程进来发现以及有缓存了,就直接走缓存。
缓存雪崩
在高并发的情况下,大量的缓存失效,或者缓存层出现故障。于是所有的请求都会到达数据库,数据库的调用量暴增,造成数据库挂掉的情况。(大量缓存失效)
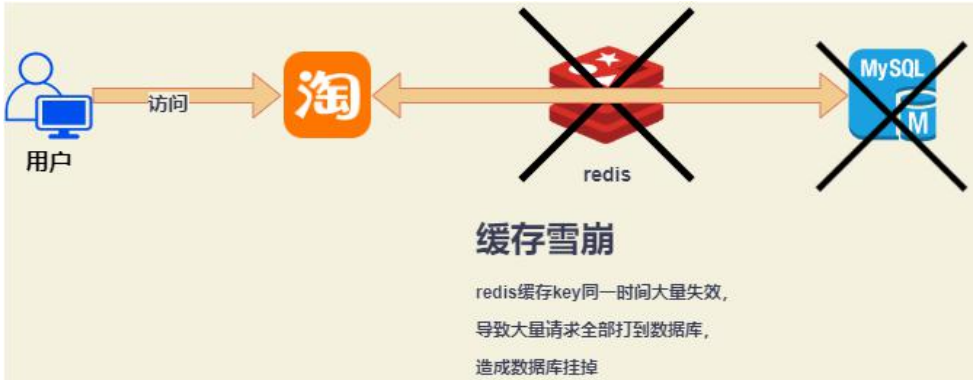
解决办法:
随机设置key失效时间,避免大量key集体失效。
若是集群部署,可将热点数据均匀分布在不同的Redis库中,也能避免key全部失效的问题。
不设置过期时间。
跑定时任务,在缓存失效前刷进新的缓存。
总结
雪崩是大面积的key缓存失效,穿透是Redis缓存里不存在的key,击穿是Redis某个热点key突然失效。
对于Redis宕机的情况,可以有以下思路:
事发前: 实现Redis的高可用(主从架构+哨兵)。尽量避免Redis挂掉。 事发中: 万一Redis挂了,可以设置本地缓存+限流。尽量避免数据库垮掉。 事发后: Redis持久化,重启后自动从磁盘加载数据,快速恢复缓存数据。
常见面试题
什么是Redis?
Redis是完全开源免费、遵守BSD协议的一个高性能key-value数据库。
Redis与其它key-value缓存产品有以下三个特点:
Redis支持数据持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list、set、zset、hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis的优势?
性能高
丰富的数据类型(Redis支持二进制案例的string、list、set、hash、zset等数据类型操作)。
原子性(Redis所有操作都是原子性的,就是要么成功执行要么失败完全不执行。单个操作也是原子性的。多个操作也支持事务)。
丰富的特性(Redis还支持publish/subscribe、通知、key过期等特性)。
Redis的数据类型?
Redis支持5种数据类型:string、hash、list、set及zset(有序集合)。
实际项目中比较常用的是string,hash。
使用Redis有哪些好处?
速度快,因为数据存在内存中,类似HashMap,HashMap的优势就是查找和操作时间复杂度都是O(1)。
支持丰富的数据类型,string、list、hash、set、zset等。
支持事务,操作都是原子性。
丰富的特性:可用于缓存、消息、设置key过期时间。
Redis是单进程单线程的?
Redis是单进程单线程的,redis团队利用技术将并发访问变为串行访问,消除了传统数据串行控制的开销。
一个字符串类型的值能存储最大容量是多少?
512M
持久化
什么是持久化?
持久化就是把内存的数据写到磁盘中去,防止服务宕机后内存数据丢失。
Redis的持久化机制是什么?各自的优缺点?
Redis提供了两种持久化机制RDB(默认)和AOF机制:
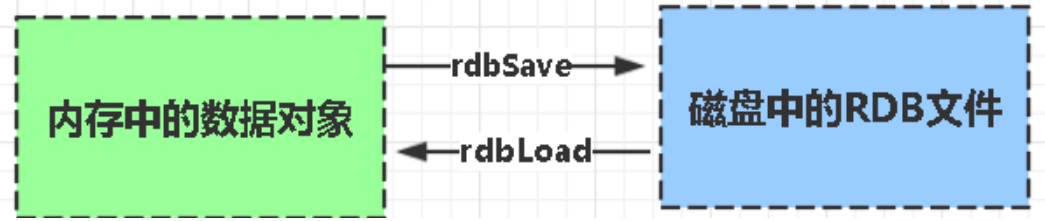
RDB:是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定时间将内存的数据以快照的形式保存在硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
优点:
只有一个文件dump.rdb,方便持久化。
容灾性好,一个文件可以保存到安全的磁盘。
性能最大化,fork子进程来完成写操作,让主进程继续处理命令,所以是IO最大化。使用单独子进程进行持久化,主进程不会进行任何IO操作,保证了Redis的高性能。
相对于数据集大时,比AOF的启动效率更高。
缺点:数据安全性低。RDB是间隔一段时间进行持久化,如果持久化之前redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候。
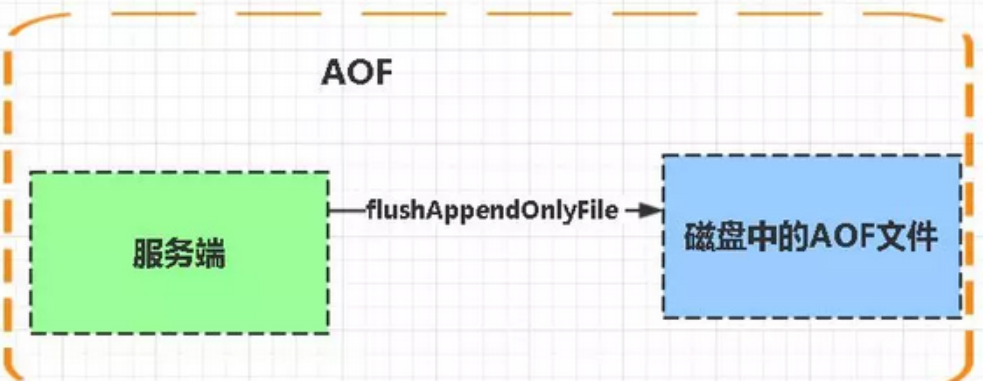
AOF:持久化
AOF持久化(Append only file),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
优点:
数据安全,AOF持久化可以配置appendfsync属性,有always,每进行一次命令操作就记录到aof文件中一次。
通过append模式写文件,即使中途宕机,可以通过redis-check-aof工具解决数据一致性问题。
AOF机制的rewrite模式。AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)。
缺点:
AOF文件比RDB文件大,且恢复速度慢。
数据集大的时候,比RDB启动效率低。
评论区